[혼자 공부하는 파이썬] 02_자료형
02-1_자료형과 문자열
*문자열 범위 선택 연산자(슬라이싱): [:]
- 범위를 지정하는 것으로 대괄호 안의 위치를 콜론(:)으로 구분하여 지정
- []연산자를 이용해 특정 위치의 문자를 참조하는 것을 인덱싱(indexing)
- [:]연산자를 이용해 문자의 일부를 추출하는 것을 슬라이싱라고 함
#ex01>
print("안녕하세요"[1:4])#결과>

문자열의 각 문자가 배열로 저장되는 것 같다. 결과값을 보고 이해해 본다면,
'안'→0번 index, '녕'→1번 index, '하'→2번 index, '세'→3번 index, '요'→4번 index
로 들어가게 되고, [1:4]의 의미는 1번 index ≤ 출력할 문자 < 4번 index가 되므로 "녕하세"가 출력된다고 생각한다.
다시 말해 [1:4]의 출력 문자는 첫 숫자부터 (뒤의숫자-1)번까지의 문자를 출력한다.
#ex02>
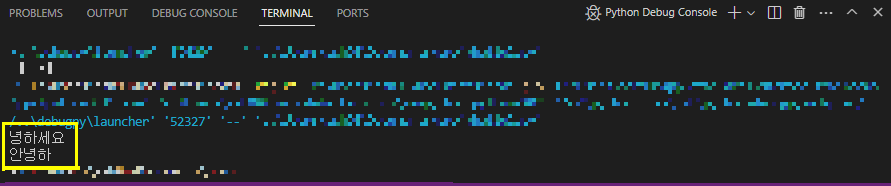
print("안녕하세요"[1:])
print("안녕하세요"[:3])첫번째 코드는 "녕하세요"를 출력하고, 두번째 코드는 "안녕하"를 출력한다. 결과를 보자.
#결과>
02-4_숫자와 문자열의 다양한 기능
index)
*문자열 양옆의 공백 제거하기 : strip()
*문자열의 format()함수
*대소문자 바꾸기 : upper(), lower()
*문자열의 format() 함수
*문자열 찾기 : find(), rfind()
*문자열과 in 연산자
*문자열 자르기 : split()
*문자열 양옆의 공백 제거하기 : strip()
- 숫자를 문자열로 변환하는 함수
- "{}".format() 으로 사용, {}의 기호가 format() 함수 괄호 안에 있는 매개변수로 대치되면서 숫자가 문자열이 되는 것(아래 예시를 보면 이해가 쉬움)
#ex03>
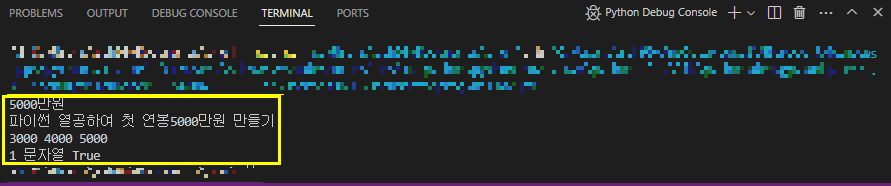
format_a = "{}만원".format(5000)
format_b = "파이썬 열공하여 첫 연봉{}만원 만들기".format(5000)
format_c = "{} {} {}".format(3000, 4000, 5000)
format_d = "{} {} {}".format(1, "문자열", True)
print(format_a)
print(format_b)
print(format_c)
print(format_d)#결과>
*대소문자 바꾸기 : upper(), lower()
- upper() : 소문자를 대문자로 변경
lower() : 대문자를 소문자로 변경
#ex03>
small = "small"
big = "BIG"
print(small)
print(small.upper())
print(big)
print(big.lower())#결과>

*문자열 양옆의 공백 제거하기 : strip()
- 댓글에서 " 안녕하세요 "이런 식의 댓글에서 양 옆의 공백을 없애 "안녕하세요"로 입력되도록 만드는데 활용
- strip() : 문자열 양 옆 공백 제거
lstrip() : 문자열 왼쪽 공백 제거
rstrip() : 문자열 오른쪽 공백 제거
#ex04>
input_a = input("입력해주세요 >")
print(input_a.strip())#결과>

*문자열 찾기 : find(), rfind()
- find() : 왼쪽부터 처음 등장하는 위치를 찾음
rfind() : 오른쪽부터 처음 등장하는 위치를 찾음
#ex05>
output_a = "자고싶다"
print(output_a)
print(output_a.find("자"))
print(output_a.find("고"))
print(output_a.find("싶"))
print(output_a.find("다"))
output_b = "하하호호하하세요"
print(output_b)
print(output_b.rfind("하하"))
print(output_b.rfind("하"))
print(output_b.find("하하"))
print(output_b.find("하"))첫번째 단락 예시는 문자열은 배열 index처럼 저장되는 것으로 추정되므로 "자고싶다"는 '자'→0번 index, '고'→1번 index, '싶'→2번 index, '다'→3번 이므로 예상 결과는 0 1 2 3을 출력할 것으로 추정된다.
두번째 단락 예시에서도 저장되는 인덱스는 첫번째와 같은 맥락으로 저장이 되는데, rfind("하하")는 오른쪽에서 찾아 들어가므로 4를 출력할 것으로 예상된다. rfind("하")는 5를 출력할 것으로 예상되며, find("하하")와 find("하")는 왼쪽에서 찾아들어가므로 둘다 0을 출력할 것으로 예상된다. 결과를 보자
#결과>

*문자열과 in 연산자
- 문자열 내부에 찾으려 하는 문자열이 있는지 확인할 때 사용, 출력은 True와 False로 나옴
#ex06>
print("안녕" in "안녕하세요")
print("가세요" in "안녕하세요")"안녕하세요"에 "안녕"이 있으므로 True 출력을 예상하며, "안녕하세요"에 "가세요"는 없으므로 False 출력을 예상한다.
#결과>

*문자열 자르기 : split()
- 문자열을 특정한 문자로 자를 때 사용하는 함수로 결과로는 리스트(list)가 나옴
#ex07>
a = "10 20 30 40 50"
print(a)
print(a.split())
#결과>

참고자료
- 한빛미디어의 윤인성 저자님의 혼자 공부하는 파이썬 책을 독학하면서 복습하기 위해 정리한 내용입니다.